A data scientist is training a text classification model by using the Amazon SageMaker built-in BlazingText algorithm. There are 5 classes in the dataset, with 300 samples for category A, 292 samples for category B, 240 samples for category C, 258 samples for category D, and 310 samples for category E.
The data scientist shuffles the data and splits off 10% for testing. After training the model, the data scientist generates confusion matrices for the training and test sets.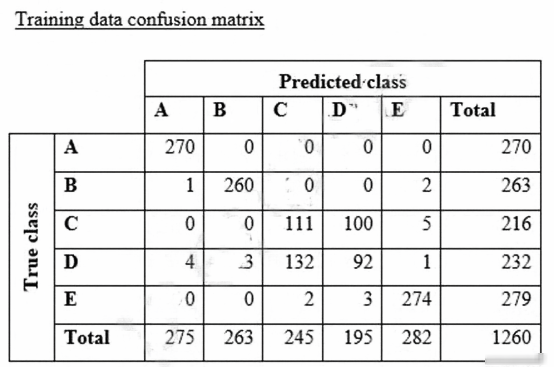
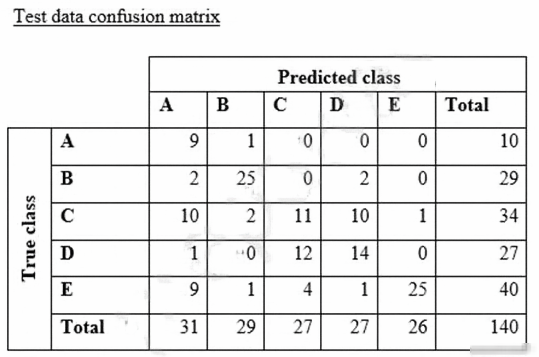
What could the data scientist conclude form these results?

LydiaGom
Highly Voted 2 years, 9 months agodolorez
Highly Voted 2 years, 8 months agoAntoh1978
Most Recent 8 months, 1 week agotueo
10 months agovkbajoria
11 months, 2 weeks agokyuhuck
1 year agoDimLam
1 year, 3 months agoDimLam
1 year, 3 months agokaike_reis
1 year, 6 months agoDimLam
1 year, 3 months agorockyykrish
1 year, 6 months agoMickey321
1 year, 6 months agoDD4
2 years, 4 months agoZSun
1 year, 9 months agotgaos
2 years, 8 months agoexam887
2 years, 8 months agobluer1
2 years, 9 months ago