Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals.
The Account table was created by using the following Transact-SQL statement: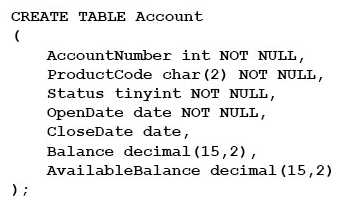
There are more than 1 billion records in the Account table. The Account Number column uniquely identifies each account. The ProductCode column has 100 different values. The values are evenly distributed in the table. Table statistics are refreshed and up to date.
You frequently run the following Transact-SQL SELECT statements:
You must avoid table scans when you run the queries.
You need to create one or more indexes for the table.
Solution: You run the following Transact-SQL statement:
CREATE NONCLUSTERED INDEX IX_Account_ProductCode ON Account(ProductCode);
Does the solution meet the goal?

New_user
Highly Voted 5 years, 4 months agoBartek
5 years, 3 months agoJohnFan
5 years, 2 months agoJohnFan
5 years, 2 months agoJawwadAK
5 years, 2 months agoMML
4 years, 10 months agoeggzamtaker
Most Recent 4 years, 4 months agoTheDUdeu
4 years, 4 months agoTheDUdeu
4 years, 5 months agoAlex5x
4 years, 5 months agoHoglet
4 years, 5 months agoAlex5x
4 years, 6 months agoLuzix
4 years, 6 months agoHoglet
4 years, 5 months agoZSQL
4 years, 6 months agoZSQL
4 years, 6 months agoHoglet
4 years, 5 months agogiuPigna
4 years, 6 months agoLuzix
4 years, 6 months agogiuPigna
4 years, 5 months agoSoupDJ
4 years, 6 months agoOooo
4 years, 7 months agodatabasejamdown
4 years, 7 months agostm22
4 years, 10 months agogeekeek1
4 years, 4 months agostm22
4 years, 10 months agostm22
4 years, 10 months agoCharlieBrownIsGreat
4 years, 5 months agostm22
4 years, 10 months agomrn0107
4 years, 11 months agoHoglet
4 years, 5 months ago