Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series.
Information and details provided in a question apply only to that question.
You have a Microsoft SQL Server database named DB1 that contains the following tables: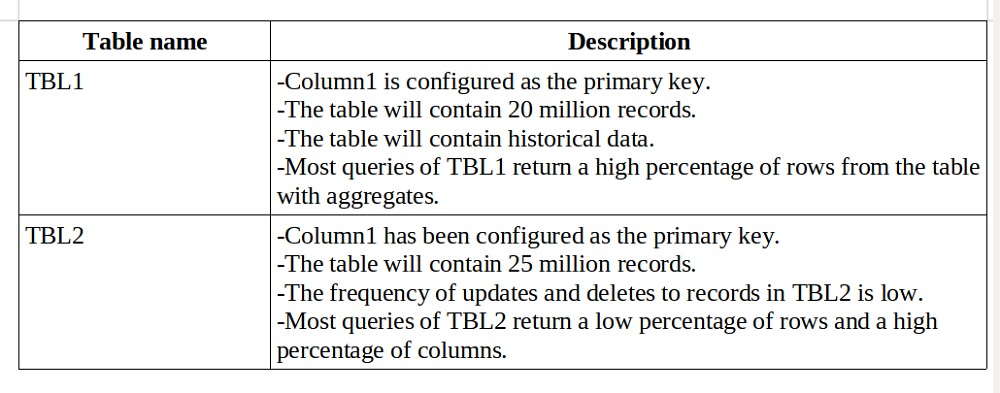
There are no foreign key relationships between TBL1 and TBL2.
You need to minimize the amount of time required for queries that use data from TB1 and TBL2 to return data.
What should you do?

vrab
4 years, 5 months agostm22
4 years, 11 months agoCococo
4 years, 9 months agoVijayglobal
5 years, 1 month agoMosufe
4 years, 10 months agoCococo
4 years, 10 months agoCococo
4 years, 10 months agoBartek
5 years, 4 months agoNickname17
5 years, 2 months agoMosufe
4 years, 10 months agoNickname17
5 years, 2 months agoStereoInvestigation
5 years, 4 months agoLuzix
4 years, 7 months agokimalto452
4 years, 6 months ago