HOTSPOT -
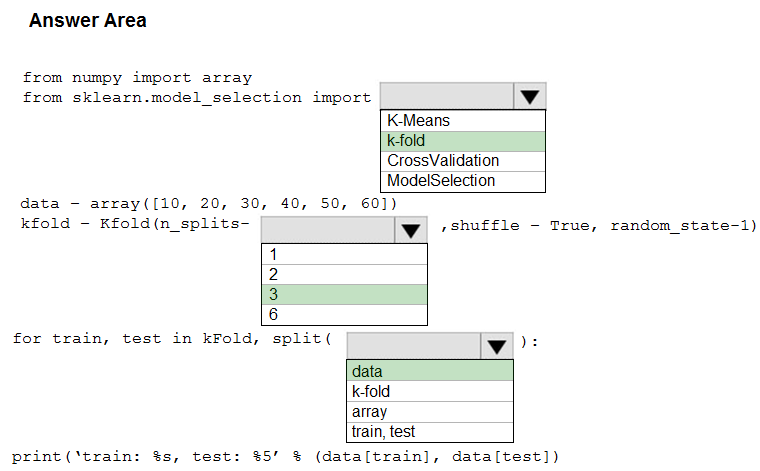
You are evaluating a Python NumPy array that contains six data points defined as follows: data = [10, 20, 30, 40, 50, 60]
You must generate the following output by using the k-fold algorithm implantation in the Python Scikit-learn machine learning library: train: [10 40 50 60], test: [20 30] train: [20 30 40 60], test: [10 50] train: [10 20 30 50], test: [40 60]
You need to implement a cross-validation to generate the output.
How should you complete the code segment? To answer, select the appropriate code segment in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area: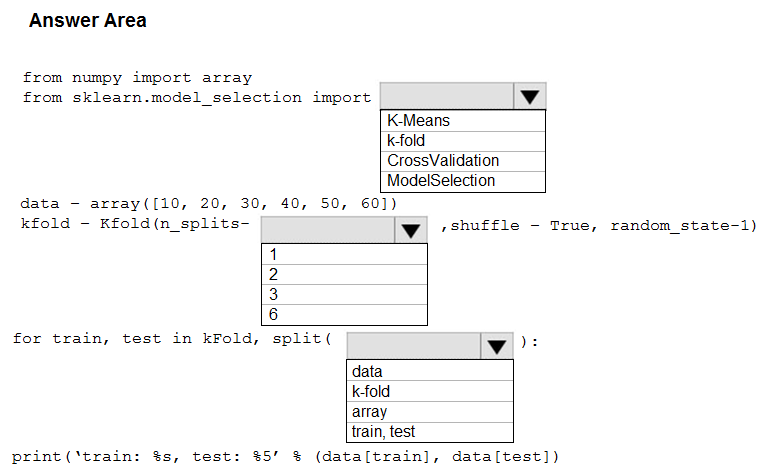

podval
Highly Voted 4 years, 4 months agoDavid_Tadeu
2 years, 7 months agoljljljlj
Highly Voted 3 years, 4 months agoMatt2000
Most Recent 10 months agoMatt2000
10 months, 2 weeks agoHisayuki
1 year, 1 month agoning
2 years, 6 months ago