HOTSPOT -
You have a database that includes a table named dbo.Sales. The table contains two billion rows. You created the table by running the following Transact-SQL statement:
You run the following queries against the dbo.Sales. All the queries perform poorly.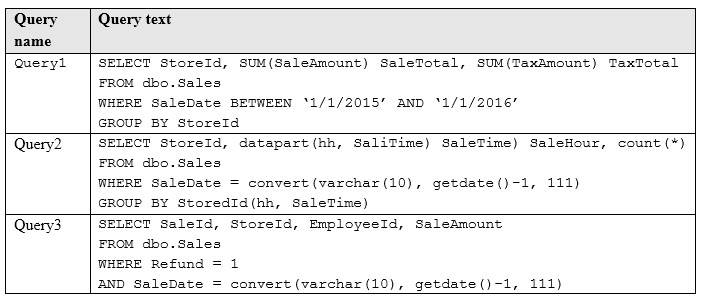
The ETL process that populates the table uses bulk insert to load 10 million rows each day. The process currently takes six hours to load the records.
The value of the Refund column is equal to 1 for only 0.01 percent of the rows in the table. For all other rows, the value of the Refund column is equal to 0.
You need to maximize the performance of queries and the ETL process.
Which index type should you use for each query? To answer, select the appropriate index types in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Simit
4 years, 5 months agopetrutjim
4 years, 5 months ago