DRAG DROP -
You develop data engineering solutions for a company.
A project requires analysis of real-time Twitter feeds. Posts that contain specific keywords must be stored and processed on Microsoft Azure and then displayed by using Microsoft Power BI. You need to implement the solution.
Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place: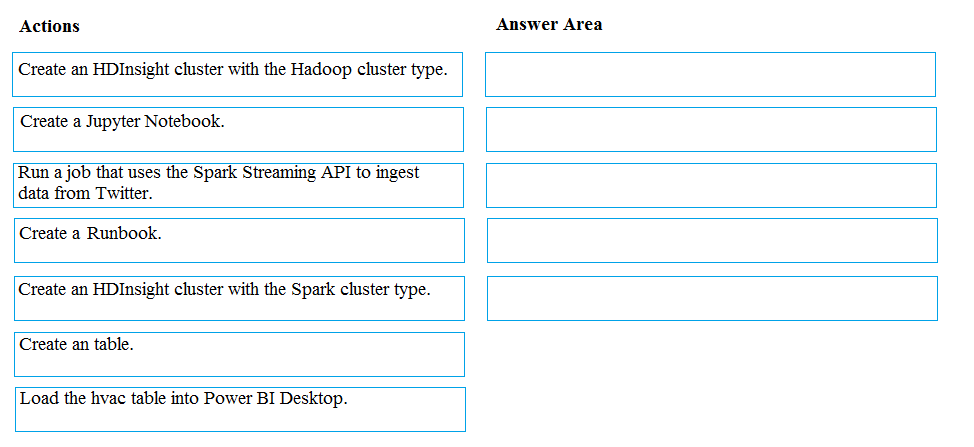


cadio30
Highly Voted 4 years, 1 month agocadio30
4 years, 1 month agoAragorn_2021
Most Recent 4 years, 1 month agoPairon
4 years, 1 month agotucho
4 years, 2 months agoJohnCrawford
4 years, 2 months ago