You create a datastore named training_data that references a blob container in an Azure Storage account. The blob container contains a folder named csv_files in which multiple comma-separated values (CSV) files are stored.
You have a script named train.py in a local folder named ./script that you plan to run as an experiment using an estimator. The script includes the following code to read data from the csv_files folder:
You have the following script.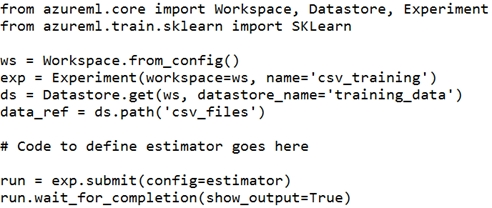
You need to configure the estimator for the experiment so that the script can read the data from a data reference named data_ref that references the csv_files folder in the training_data datastore.
Which code should you use to configure the estimator?
A.
B.
C.
D.
E.

chaudha4
Highly Voted 3 years, 3 months agoscipio
3 years, 3 months agovv_bb
Most Recent 9 months, 1 week agoiai
1 year, 2 months agodanishanis
1 year, 5 months agojpalaci22
1 year, 6 months agoEdriv
1 year, 8 months agoning
2 years, 3 months agoTheYazan
2 years, 5 months agokisskeo
2 years, 10 months agoljljljlj
3 years, 1 month agosarahmoin
3 years, 2 months agovhx
3 years, 2 months agoiai
1 year, 2 months agoiuolu
3 years, 3 months agochaudha4
3 years, 3 months ago