You are designing a fact table named FactPurchase in an Azure Synapse Analytics dedicated SQL pool. The table contains purchases from suppliers for a retail store. FactPurchase will contain the following columns.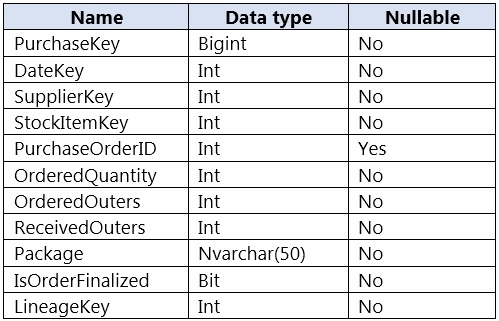
FactPurchase will have 1 million rows of data added daily and will contain three years of data.
Transact-SQL queries similar to the following query will be executed daily.
SELECT -
SupplierKey, StockItemKey, COUNT(*)
FROM FactPurchase -
WHERE DateKey >= 20210101 -
AND DateKey <= 20210131 -
GROUP By SupplierKey, StockItemKey
Which table distribution will minimize query times?

AugustineUba
Highly Voted 3 years, 11 months agoYipingRuan
3 years, 8 months agocem_kalender
2 years, 8 months agoYipingRuan
3 years, 8 months agowaterbender19
Highly Voted 3 years, 11 months agowaterbender19
3 years, 11 months agoLucky_me
3 years, 6 months agokamil_k
3 years, 3 months agoAnandEMani
3 years, 10 months agokamil_k
3 years, 3 months agoAmmy_b
Most Recent 3 months, 2 weeks agojay0809
3 months, 2 weeks agoIMadnan
4 months, 2 weeks agodippip123
4 months, 3 weeks agosamirarian
4 months, 3 weeks agoJustImperius
5 months, 2 weeks agonockda
6 months, 2 weeks agonockda
6 months, 3 weeks agoDaniel627
7 months agof7c717f
7 months agomoize
7 months agoEmnCours
7 months, 1 week agonockda
7 months, 1 week agonockda
7 months, 2 weeks agorenan_ineu
10 months, 2 weeks ago