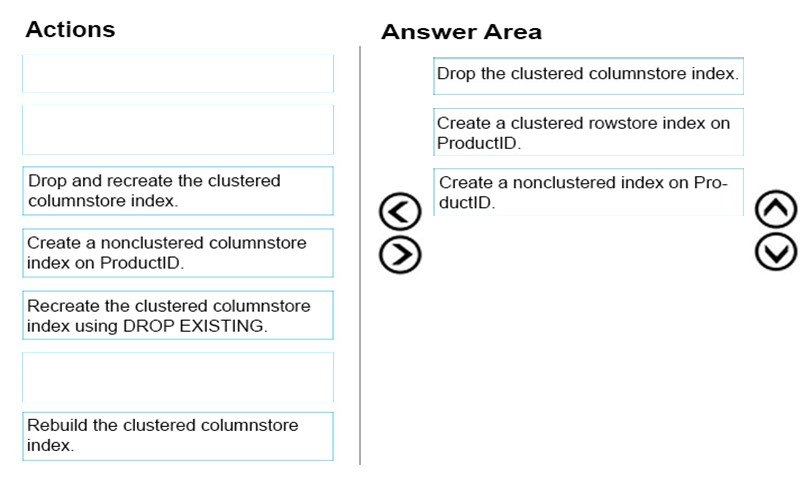
DRAG DROP -
You administer a database that is used for reporting purposes. The database has a large fact table that contains three hundred million rows. The table includes a clustered columnstore index and a nonclustered index on the ProductID column. New rows are inserted into the table every day.
Performance of queries that filter the Product ID column have degraded significantly.
You need to improve the performance of the queries.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:

Som2020
4 years, 6 months agoHoglet
4 years, 5 months agoMelKr
5 years, 1 month agoHoglet
4 years, 5 months agoTheSwedishGuy
5 years, 4 months agoHoglet
4 years, 5 months agomrn0107
5 years, 5 months agoTheSwedishGuy
5 years, 5 months agotomzus
5 years, 7 months agoVarad
5 years, 8 months agoHoglet
4 years, 5 months agoVarad
5 years, 8 months agorobiciccio
5 years, 8 months agoRohitM
5 years, 9 months ago