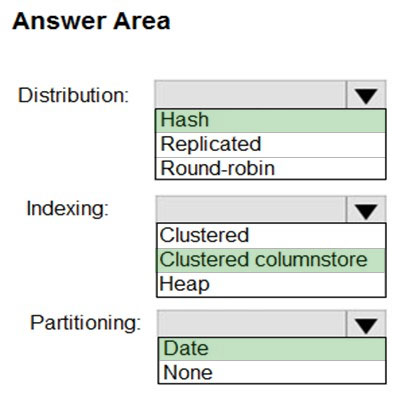
HOTSPOT -
You have a SQL pool in Azure Synapse.
You plan to load data from Azure Blob storage to a staging table. Approximately 1 million rows of data will be loaded daily. The table will be truncated before each daily load.
You need to create the staging table. The solution must minimize how long it takes to load the data to the staging table.
How should you configure the table? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area: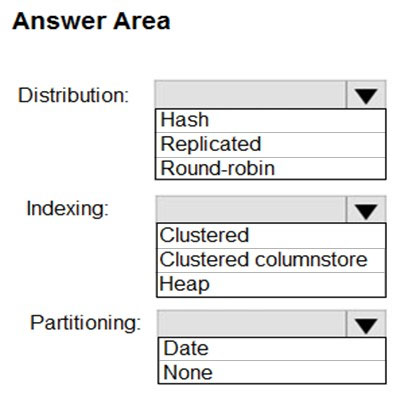

A1000
Highly Voted 3 years, 11 months agogssd4scoder
3 years, 9 months agoDrTaz
3 years, 7 months agoroopansh.gupta2
11 months, 2 weeks agoNarasimhap
3 years, 5 months agoHomer23
1 year, 4 months agolaszek
Highly Voted 3 years, 11 months agoberserksap
3 years, 9 months agoandy_g
3 years, 5 months agoVardhan_Brahmanapally
3 years, 9 months agoDrTaz
3 years, 7 months agoSQLDev0000
3 years, 5 months agoHaliBrickclay
Most Recent 10 months, 1 week agoVeroDon
3 years, 7 months agoSasha_in_San_Francisco
10 months, 1 week agojhargett1
10 months, 1 week agoakk_1289
10 months, 1 week ago74gjd_37
10 months, 1 week agoMBRSDG
10 months, 1 week agoiceberge
1 year agoRakshithaReddy
1 year, 2 months agoDusica
1 year, 3 months agoAlongi
1 year, 3 months ago__Tom
1 year, 8 months agokkk5566
1 year, 11 months agokkk5566
1 year, 11 months agojanaki
2 years, 2 months agorocky48
2 years, 3 months ago