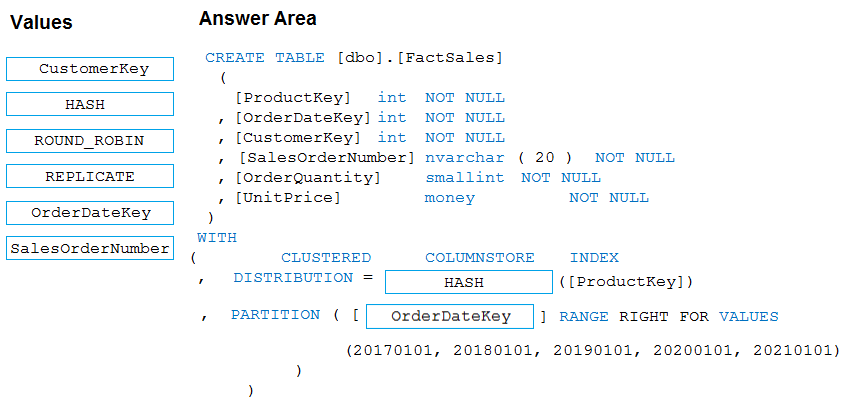
DRAG DROP -
You plan to create a table in an Azure Synapse Analytics dedicated SQL pool.
Data in the table will be retained for five years. Once a year, data that is older than five years will be deleted.
You need to ensure that the data is distributed evenly across partitions. The solutions must minimize the amount of time required to delete old data.
How should you complete the Transact-SQL statement? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all.
You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place: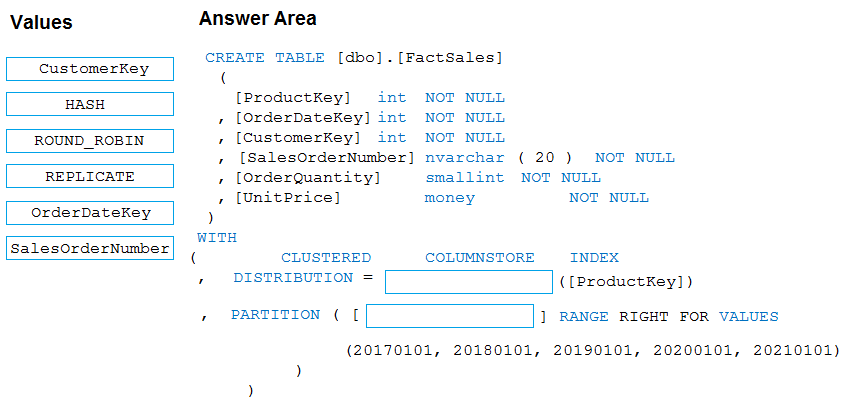

learnazureportal
Highly Voted 10 months, 2 weeks agoU_C
10 months, 1 week agoU_C
3 years, 9 months agoMladen_66
Highly Voted 3 years, 11 months agoramelas
3 years, 7 months agoo2091
Most Recent 3 years, 8 months agomatongax
3 years, 9 months agocaptainpike
3 years, 10 months agoAggie0702
3 years, 10 months agoAggie0702
3 years, 10 months agoovokpus
3 years, 11 months agoo2091
3 years, 8 months agomaple580122
3 years, 11 months ago