HOTSPOT -
You have an Azure Storage account that generates 200,000 new files daily. The file names have a format of {YYYY}/{MM}/{DD}/{HH}/{CustomerID}.csv.
You need to design an Azure Data Factory solution that will load new data from the storage account to an Azure Data Lake once hourly. The solution must minimize load times and costs.
How should you configure the solution? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

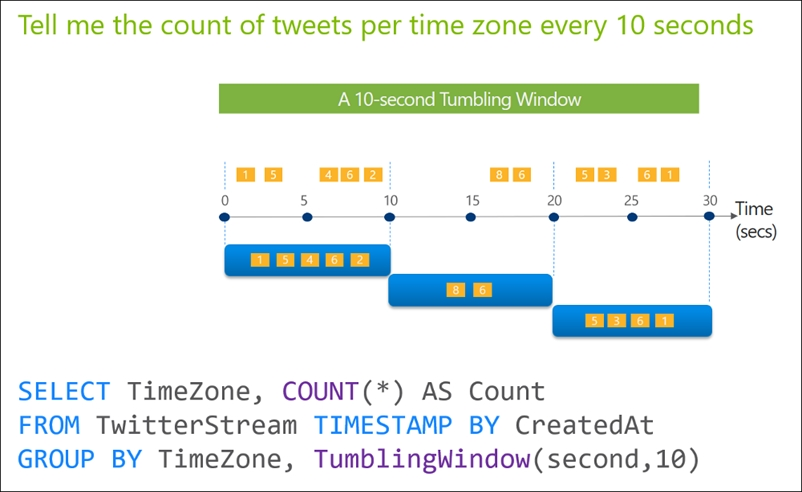

onyerleft
Highly Voted 2 years, 10 months agomav2000
8 months, 1 week agoMBRSDG
7 months ago_Ahan_
5 months, 1 week agoGikan
9 months agoxcsakubara
Highly Voted 2 years, 8 months agophydev
1 year agopositivitypeople
Most Recent 10 months, 1 week agoMomoanwar
10 months, 3 weeks agoAndrew_Chen
1 year agoauwia
1 year, 4 months agovedantnj
1 year, 5 months agoRossana
1 year, 6 months agomav2000
8 months, 1 week agomartcerv
1 year, 10 months agoDeeksha1234
2 years, 2 months agojskibick
2 years, 5 months agoMassy
2 years, 7 months agoBoompiee
2 years, 5 months agoxcsakubara
2 years, 8 months agosparkchu
2 years, 7 months agojv2120
2 years, 10 months agojv2120
2 years, 10 months agoAyan3B
2 years, 10 months agoItHYMeRIsh
2 years, 10 months agoANath
2 years, 9 months ago