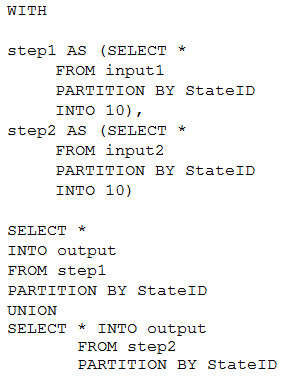
HOTSPOT - You have the following Azure Stream Analytics query. For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:
Suggested Answer:
Box 1: No - Note: You can now use a new extension of Azure Stream Analytics SQL to specify the number of partitions of a stream when reshuffling the data. The outcome is a stream that has the same partition scheme. Please see below for an example: WITH step1 AS (SELECT * FROM [input1] PARTITION BY DeviceID INTO 10), step2 AS (SELECT * FROM [input2] PARTITION BY DeviceID INTO 10) SELECT * INTO [output] FROM step1 PARTITION BY DeviceID UNION step2 PARTITION BY DeviceID Note: The new extension of Azure Stream Analytics SQL includes a keyword INTO that allows you to specify the number of partitions for a stream when performing reshuffling using a PARTITION BY statement.
Box 2: Yes - When joining two streams of data explicitly repartitioned, these streams must have the same partition key and partition count.
Box 3: Yes - Streaming Units (SUs) represents the computing resources that are allocated to execute a Stream Analytics job. The higher the number of SUs, the more CPU and memory resources are allocated for your job. In general, the best practice is to start with 6 SUs for queries that don't use PARTITION BY. Here there are 10 partitions, so 6x10 = 60 SUs is good. Note: Remember, Streaming Unit (SU) count, which is the unit of scale for Azure Stream Analytics, must be adjusted so the number of physical resources available to the job can fit the partitioned flow. In general, six SUs is a good number to assign to each partition. In case there are insufficient resources assigned to the job, the system will only apply the repartition if it benefits the job. Reference: https://azure.microsoft.com/en-in/blog/maximize-throughput-with-repartitioning-in-azure-stream-analytics/ https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-streaming-unit-consumption
I feel its all YES. Since it does use a UNION and UNION combines. No matter it repartitions the result is the combination of two sources, a UNION of two sources. Am I missing something here?
I believe the answer to the first question heavily relies on creator's understanding "what is query". If it is the last part only (without CTEs) than the answer should be "yes", because you have partitioned data that come from CTEs as input for the main query. But if creator's understaning that query is the whole thing, than probably answer should be "no", because you're receiving non-partitioned data from sensors.
False, True, False.
https://learn.microsoft.com/en-us/azure/stream-analytics/repartition
The first is False, because this:
"The following example query joins two streams of repartitioned data."
It's extracted from the link above, and it's pointing to our query! Repartitioned and not partitioned.
Second is True, it's explicitly written
The output scheme should match the stream scheme key and count so that each substream can be flushed independently.
Third is False,
"In general, six SUs are needed for each partition."
In the example we have 10 positions for step 1 and 10 for step 2, it should be 120 and not 60.
1) Y
2) Y The output scheme should match the stream scheme key and count so that each substream can be flushed independently. https://learn.microsoft.com/en-us/azure/stream-analytics/repartition
3) Y
False, True, False.
https://learn.microsoft.com/en-us/azure/stream-analytics/repartition
The first is False, because this:
"The following example query joins two streams of repartitioned data."
It's extracted from the link above, and it's pointing to our query! Repartitioned and not partitioned.
Second is True, it's explicitly written
The output scheme should match the stream scheme key and count so that each substream can be flushed independently.
Third is False,
"In general, six SUs are needed for each partition."
In the example we have 10 positions for step 1 and 10 for step 2, it should be 120 and not 60.
The first question should be yes. "Partitioning lets you divide data into subsets based on a partition key". https://learn.microsoft.com/en-us/azure/stream-analytics/stream-analytics-parallelization
Chatgpt say : yes tes no.
Based on the provided information and additional documentation on Azure Stream Analytics:
1. **Yes**: The query combines two streams of partitioned data [[❞]](https://azure.microsoft.com/fr-fr/blog/maximize-throughput-with-repartitioning-in-azure-stream-analytics/).
2. **Yes**: The stream scheme key and count should match the output scheme for optimal independent processing of each substream [[❞]](https://azure.microsoft.com/fr-fr/blog/maximize-throughput-with-repartitioning-in-azure-stream-analytics/).
3. **No**: The documentation does not specify that providing 60 streaming units will optimize the query's performance. The appropriate number of streaming units depends on experimentation and resource usage observation [[❞]](https://azure.microsoft.com/fr-fr/blog/maximize-throughput-with-repartitioning-in-azure-stream-analytics/).
The answer you need for first and second questions is in Microsoft Documentation:
"The following example query joins two streams of repartitioned data. When joining two streams of repartitioned data, the streams must have the same partition key and count. The outcome is a stream that has the same partition scheme. (...) The output scheme should match the stream scheme key and count so that each substream can be flushed independently. " https://learn.microsoft.com/en-us/azure/stream-analytics/repartition#repartition-input-within-a-single-stream-analytics-job
So its not two streams of partitioned data, but two streams of REpartitioned data.
And the output stream must have the same partition key and count.
For the third question, a bit lower in the same link, we get: In general, six SUs are needed for each partition. Therefore, if we have 10 partitions, 6*10 = 60.
I will correct my previous message. After reading through SU calculation documentation, I concluded it should be 120 for SU V1 or 20 for SU V2. Therefore none of them would be 60.
Explanation is this sentence here:
"All non-partitioned steps together can scale up to one streaming unit (SU V2s) for a Stream Analytics job. In addition, you can add 1 SU V2 for each partition in a partitioned step.
So tecnically, it would be 21 SU V2.
Therefore, 60 SU is not correct.
Should be
FALSE
TRUE
FALSE
Calculate the max streaming units for a job
All non-partitioned steps together can scale up to one streaming unit (SU V2s) for a Stream Analytics job. In addition, you can add 1 SU V2 for each partition in a partitioned step. You can see some examples in the table below.
Query Max SUs for the job
The query contains one step.
The step isn't partitioned.
1 SU V2
The input data stream is partitioned by 16.
The query contains one step.
The step is partitioned.
16 SU V2 (1 * 16 partitions)
The query contains two steps.
Neither of the steps is partitioned.
1 SU V2
The input data stream is partitioned by 3.
The query contains two steps. The input step is partitioned and the second step isn't.
The SELECT statement reads from the partitioned input.
4 SU V2s (3 for partitioned steps + 1 for non-partitioned steps
Base on the above from MS documentation, why do we need to multiply by 6SUs?
I think this is an older question since there is SU V2 now.
According to this: https://learn.microsoft.com/en-us/azure/stream-analytics/stream-analytics-parallelization
Each partition would consume 1 Streamiung Unit (SU) V2 and since we have 2 inputs with 10 partitions each it would add up to 20 SU V2, now we have 2 Select statements after the WITH Step which each consume 1 SU V2, so it should add up to 22 SU V2 which would equal 22*6=132 SU V1.
Based on recommended Streaming units,
Step 1: 10 partitions
Step 2: 10 partitions
(1*10+1*10) = 20 SU's is the optimal, if you have more, it's not ideal because some SU's are inactive and if you have less, it can cause a bottleneck
https://learn.microsoft.com/en-us/azure/stream-analytics/stre
am-analytics-parallelization#calculate-the-maximum-streaming-units-of-a-job
Question 1 is false; the question says the union of streams and not data. The union combines 2 streams which are the same and thus, the output is the same stream.
1. True
2. False:
In the context of a UNION operation in Azure Stream Analytics, the stream scheme key and count do not need to match the output schema. The key and count of the output schema are determined based on the input streams being unioned.
When performing a UNION operation, the input streams must have compatible schemas, which means that the data types and field names should align. However, the key and count are determined by the input streams themselves and do not need to match the output schema.
3. True
False, true, false.
I've changed mind completely looking and reading accurately this official link where all 3 questions are answered:
https://learn.microsoft.com/en-us/azure/stream-analytics/repartition
The first is False, because this:
"The following example query joins two streams of repartitioned data."
It's extracted from the link above, and it's pointing to our query! Repartitioned and not partitioned.
Second is True, it's explicitly written
The output scheme should match the stream scheme key and count so that each substream can be flushed independently.
Third is False,
"In general, six SUs are needed for each partition."
In the example we have 10 positions for step 1 and 10 for step 2, it should be 120 and not 60.
Again for point 2-False:
https://learn.microsoft.com/en-us/stream-analytics-query/union-azure-stream-analytics
The following are basic rules for combining the result sets of two queries by using UNION:
- The number and the order of the columns must be the same in all queries.
- The data types must be compatible.
- Streams must have the same partition and partition count (not scheme key and count! :-) )
I believe the answer to the First Question is No because the execution of the last statement will result in an error because the second query has "SELECT INTO output" rather than a straight SELECT. Can anyone confirm that you can UNION two data sets both directed to the same stream with SELECT INTO? It's not functionality shown in any example I've been able to find (in the given answer, linked in other comments on here, and my own research).
Is the first option NO because it mentions partitioned data instead of repartitioned data?
Reference : https://learn.microsoft.com/en-us/azure/stream-analytics/repartition
The following example query joins two streams of repartitioned data. When joining two streams of repartitioned data, the streams must have the same partition key and count. The outcome is a stream that has the same partition scheme.
WITH step1 AS (SELECT * FROM input1 PARTITION BY DeviceID),
step2 AS (SELECT * FROM input2 PARTITION BY DeviceID)
SELECT * INTO output FROM step1 PARTITION BY DeviceID UNION step2 PARTITION BY DeviceID
yes, the only difference I see is this:
1)this example:
SELECT *
INTO output
FROM
step1 PARTITION BY StateID
UNION
SELECT * INTO output FROM step2 PARTITION BY StateID #is using another select * on top of step2
2)the doc example:
SELECT * INTO output
FROM
step1 PARTITION BY DeviceID
UNION
step2 PARTITION BY DeviceID
I think both query joins two streams of repartitioned/partitioned data, so first answer should be yes
This section is not available anymore. Please use the main Exam Page.DP-203 Exam Questions
Log in to ExamTopics
Sign in:
Community vote distribution
A (35%)
C (25%)
B (20%)
Other
Most Voted
A voting comment increases the vote count for the chosen answer by one.
Upvoting a comment with a selected answer will also increase the vote count towards that answer by one.
So if you see a comment that you already agree with, you can upvote it instead of posting a new comment.



objecto
Highly Voted 3 years agooleg25
1 year, 8 months agoauwia
Highly Voted 2 years agoDusica
1 year, 1 month agosamianae
Most Recent 5 months agoff5037f
8 months agodgerok
1 year, 2 months agorocky48
1 year, 4 months agoHa_Tran
1 year, 4 months agoAnto____
1 year, 4 months agoMomoanwar
1 year, 6 months agodakku987
1 year, 5 months agoellala
1 year, 8 months agoellala
1 year, 8 months agoahmadsayeed
1 year, 7 months agoVanq69
1 year, 8 months agomav2000
1 year, 8 months agoSaintu
1 year, 10 months agoauwia
2 years agoauwia
2 years agoauwia
2 years agokkk5566
1 year, 9 months agokkk5566
1 year, 9 months agoUristMcFarmer
2 years, 5 months agorohanb1986
2 years, 6 months agovrodriguesp
2 years, 4 months agoXiltroX
2 years, 6 months ago