DRAG DROP -
You are developing the smart e-commerce project.
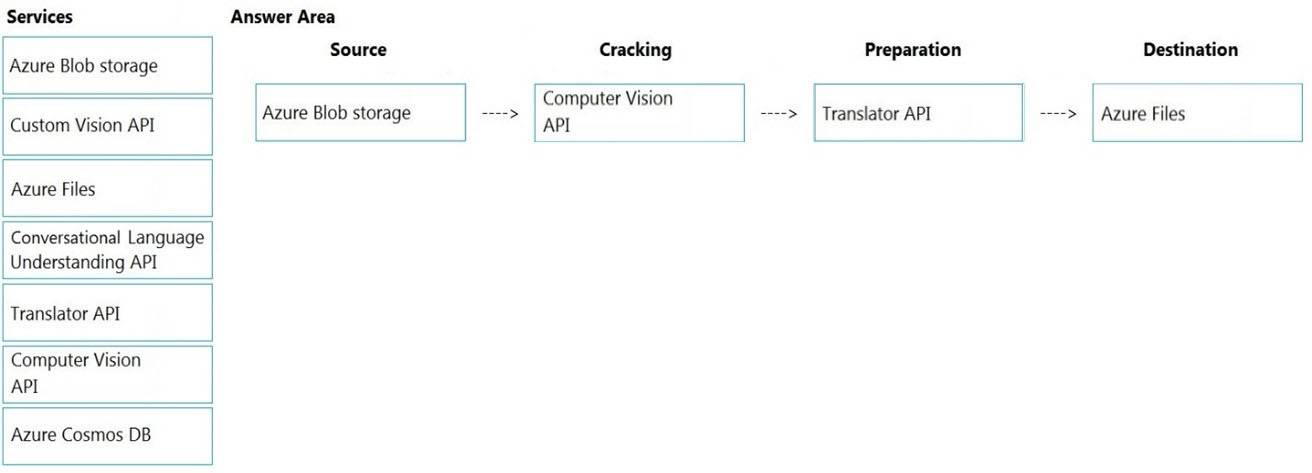
You need to design the skillset to include the contents of PDFs in searches.
How should you complete the skillset design diagram? To answer, drag the appropriate services to the correct stages. Each service may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place: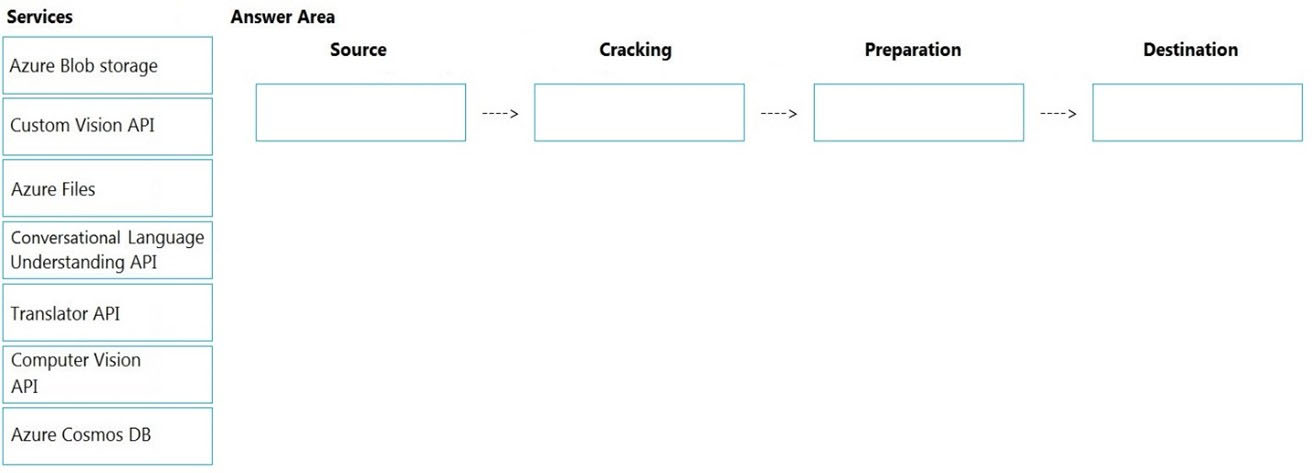

M25
Highly Voted 1 year, 11 months agoM25
1 year, 11 months agoM25
1 year, 11 months agordemontis
1 year, 8 months agoSharks82
Highly Voted 2 years, 10 months agotech_rum
Most Recent 3 months agosyupwsh
5 months agosyupwsh
5 months agoGoldBear
1 year, 1 month agorookiee1111
1 year, 1 month agorookiee1111
1 year, 1 month ago