A company employs a team of customer service agents to provide telephone and email support to customers.
The company develops a webchat bot to provide automated answers to common customer queries.
Which business benefit should the company expect as a result of creating the webchat bot solution?
Correct Answer:
B
🗳️
For a machine learning progress, how should you split data for training and evaluation?
Correct Answer:
B
🗳️
HOTSPOT -
You are developing a model to predict events by using classification.
You have a confusion matrix for the model scored on test data as shown in the following exhibit.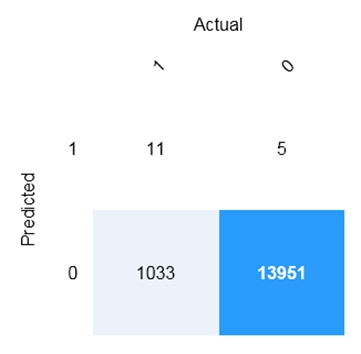
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:

Box 1: 11 -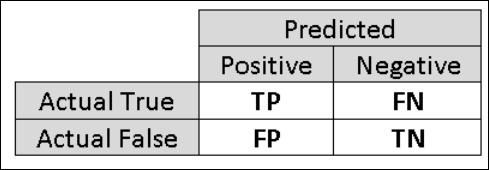
TP = True Positive.
The class labels in the training set can take on only two possible values, which we usually refer to as positive or negative. The positive and negative instances that a classifier predicts correctly are called true positives (TP) and true negatives (TN), respectively. Similarly, the incorrectly classified instances are called false positives (FP) and false negatives (FN).
Box 2: 1,033 -
FN = False Negative -
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/studio/evaluate-model-performance
You build a machine learning model by using the automated machine learning user interface (UI).
You need to ensure that the model meets the Microsoft transparency principle for responsible AI.
What should you do?
Correct Answer:
B
🗳️
HOTSPOT -
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:

Anomaly detection encompasses many important tasks in machine learning:
Identifying transactions that are potentially fraudulent.
Learning patterns that indicate that a network intrusion has occurred.
Finding abnormal clusters of patients.
Checking values entered into a system.
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/anomaly-detection
By buying Contributor Access for yourself, you will gain the following features:

