You are a data engineer implementing a lambda architecture on Microsoft Azure. You use an open-source big data solution to collect, process, and maintain data.
The analytical data store performs poorly.
You must implement a solution that meets the following requirements:
✑ Provide data warehousing
✑ Reduce ongoing management activities
✑ Deliver SQL query responses in less than one second
You need to create an HDInsight cluster to meet the requirements.
Which type of cluster should you create?
Correct Answer:
D
🗳️
Lambda Architecture with Azure:
Azure offers you a combination of following technologies to accelerate real-time big data analytics:
1. Azure Cosmos DB, a globally distributed and multi-model database service.
2. Apache Spark for Azure HDInsight, a processing framework that runs large-scale data analytics applications.
3. Azure Cosmos DB change feed, which streams new data to the batch layer for HDInsight to process.
4. The Spark to Azure Cosmos DB Connector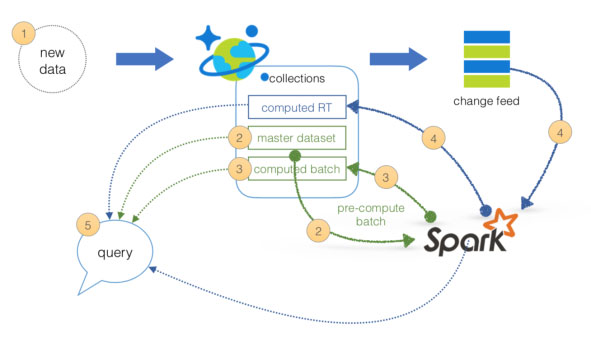
Note: Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch processing and stream processing methods, and minimizing the latency involved in querying big data.
References:
https://sqlwithmanoj.com/2018/02/16/what-is-lambda-architecture-and-what-azure-offers-with-its-new-cosmos-db/
DRAG DROP -
You develop data engineering solutions for a company. You must migrate data from Microsoft Azure Blob storage to an Azure SQL Data Warehouse for further transformation. You need to implement the solution.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Correct Answer:
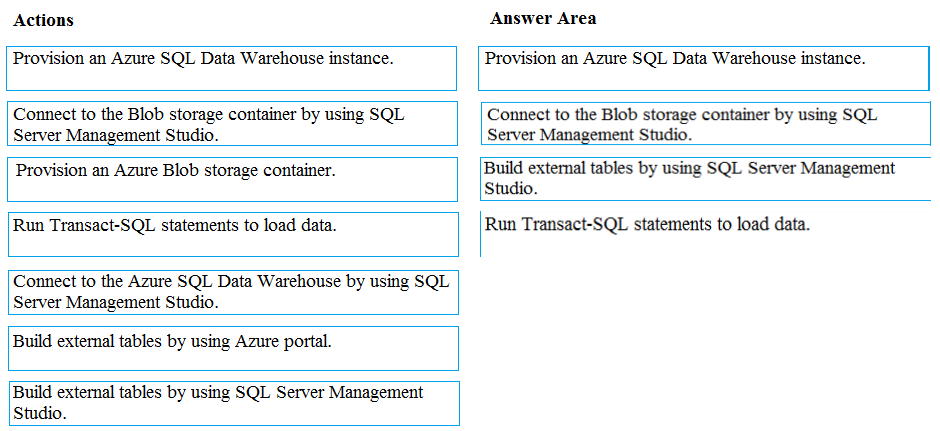
Step 1: Provision an Azure SQL Data Warehouse instance.
Create a data warehouse in the Azure portal.
Step 2: Connect to the Azure SQL Data warehouse by using SQL Server Management Studio
Connect to the data warehouse with SSMS (SQL Server Management Studio)
Step 3: Build external tables by using the SQL Server Management Studio
Create external tables for data in Azure blob storage.
You are ready to begin the process of loading data into your new data warehouse. You use external tables to load data from the Azure storage blob.
Step 4: Run Transact-SQL statements to load data.
You can use the CREATE TABLE AS SELECT (CTAS) T-SQL statement to load the data from Azure Storage Blob into new tables in your data warehouse.
References:
https://github.com/MicrosoftDocs/azure-docs/blob/master/articles/sql-data-warehouse/load-data-from-azure-blob-storage-using-polybase.md
You develop data engineering solutions for a company. The company has on-premises Microsoft SQL Server databases at multiple locations.
The company must integrate data with Microsoft Power BI and Microsoft Azure Logic Apps. The solution must avoid single points of failure during connection and transfer to the cloud. The solution must also minimize latency.
You need to secure the transfer of data between on-premises databases and Microsoft Azure.
What should you do?
Correct Answer:
D
🗳️
You can create high availability clusters of On-premises data gateway installations, to ensure your organization can access on-premises data resources used in
Power BI reports and dashboards. Such clusters allow gateway administrators to group gateways to avoid single points of failure in accessing on-premises data resources. The Power BI service always uses the primary gateway in the cluster, unless it's not available. In that case, the service switches to the next gateway in the cluster, and so on.
References:
https://docs.microsoft.com/en-us/power-bi/service-gateway-high-availability-clusters
You are a data architect. The data engineering team needs to configure a synchronization of data between an on-premises Microsoft SQL Server database to
Azure SQL Database.
Ad-hoc and reporting queries are being overutilized the on-premises production instance. The synchronization process must:
✑ Perform an initial data synchronization to Azure SQL Database with minimal downtime
✑ Perform bi-directional data synchronization after initial synchronization
You need to implement this synchronization solution.
Which synchronization method should you use?
Correct Answer:
E
🗳️
SQL Data Sync is a service built on Azure SQL Database that lets you synchronize the data you select bi-directionally across multiple SQL databases and SQL
Server instances.
With Data Sync, you can keep data synchronized between your on-premises databases and Azure SQL databases to enable hybrid applications.
Compare Data Sync with Transactional Replication
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-sync-data
An application will use Microsoft Azure Cosmos DB as its data solution. The application will use the Cassandra API to support a column-based database type that uses containers to store items.
You need to provision Azure Cosmos DB. Which container name and item name should you use? Each correct answer presents part of the solutions.
NOTE: Each correct answer selection is worth one point.
Correct Answer:
BE
🗳️
B: Depending on the choice of the API, an Azure Cosmos item can represent either a document in a collection, a row in a table or a node/edge in a graph. The following table shows the mapping between API-specific entities to an Azure Cosmos item:
E: An Azure Cosmos container is specialized into API-specific entities as follows:
References:
https://docs.microsoft.com/en-us/azure/cosmos-db/databases-containers-items
A company has a SaaS solution that uses Azure SQL Database with elastic pools. The solution contains a dedicated database for each customer organization.
Customer organizations have peak usage at different periods during the year.
You need to implement the Azure SQL Database elastic pool to minimize cost.
Which option or options should you configure?
Correct Answer:
E
🗳️
The best size for a pool depends on the aggregate resources needed for all databases in the pool. This involves determining the following:
✑ Maximum resources utilized by all databases in the pool (either maximum DTUs or maximum vCores depending on your choice of resourcing model).
✑ Maximum storage bytes utilized by all databases in the pool.
Note: Elastic pools enable the developer to purchase resources for a pool shared by multiple databases to accommodate unpredictable periods of usage by individual databases. You can configure resources for the pool based either on the DTU-based purchasing model or the vCore-based purchasing model.
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-elastic-pool
HOTSPOT -
You are a data engineer. You are designing a Hadoop Distributed File System (HDFS) architecture. You plan to use Microsoft Azure Data Lake as a data storage repository.
You must provision the repository with a resilient data schema. You need to ensure the resiliency of the Azure Data Lake Storage. What should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:

Box 1: NameNode -
An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients.
Box 2: DataNode -
The DataNodes are responsible for serving read and write requests from the file system's clients.
Box 3: DataNode -
The DataNodes perform block creation, deletion, and replication upon instruction from the NameNode.
Note: HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system's clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
References:
https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html#NameNode+and+DataNodes
DRAG DROP -
You are developing the data platform for a global retail company. The company operates during normal working hours in each region. The analytical database is used once a week for building sales projections.
Each region maintains its own private virtual network.
Building the sales projections is very resource intensive and generates upwards of 20 terabytes (TB) of data.
Microsoft Azure SQL Databases must be provisioned.
✑ Database provisioning must maximize performance and minimize cost
✑ The daily sales for each region must be stored in an Azure SQL Database instance
✑ Once a day, the data for all regions must be loaded in an analytical Azure SQL Database instance
You need to provision Azure SQL database instances.
How should you provision the database instances? To answer, drag the appropriate Azure SQL products to the correct databases. Each Azure SQL product may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Correct Answer:

Box 1: Azure SQL Database elastic pools
SQL Database elastic pools are a simple, cost-effective solution for managing and scaling multiple databases that have varying and unpredictable usage demands. The databases in an elastic pool are on a single Azure SQL Database server and share a set number of resources at a set price. Elastic pools in Azure
SQL Database enable SaaS developers to optimize the price performance for a group of databases within a prescribed budget while delivering performance elasticity for each database.
Box 2: Azure SQL Database Hyperscale
A Hyperscale database is an Azure SQL database in the Hyperscale service tier that is backed by the Hyperscale scale-out storage technology. A Hyperscale database supports up to 100 TB of data and provides high throughput and performance, as well as rapid scaling to adapt to the workload requirements. Scaling is transparent to the application ג€" connectivity, query processing, and so on, work like any other SQL database.
Incorrect Answers:
Azure SQL Database Managed Instance: The managed instance deployment model is designed for customers looking to migrate a large number of apps from on- premises or IaaS, self-built, or ISV provided environment to fully managed PaaS cloud environment, with as low migration effort as possible.
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-elastic-pool https://docs.microsoft.com/en-us/azure/sql-database/sql-database-service-tier-hyperscale-faq
A company manages several on-premises Microsoft SQL Server databases.
You need to migrate the databases to Microsoft Azure by using a backup process of Microsoft SQL Server.
Which data technology should you use?
Correct Answer:
D
🗳️
Managed instance is a new deployment option of Azure SQL Database, providing near 100% compatibility with the latest SQL Server on-premises (Enterprise
Edition) Database Engine, providing a native virtual network (VNet) implementation that addresses common security concerns, and a business model favorable for on-premises SQL Server customers. The managed instance deployment model allows existing SQL Server customers to lift and shift their on-premises applications to the cloud with minimal application and database changes.
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-managed-instance
The data engineering team manages Azure HDInsight clusters. The team spends a large amount of time creating and destroying clusters daily because most of the data pipeline process runs in minutes.
You need to implement a solution that deploys multiple HDInsight clusters with minimal effort.
What should you implement?
Correct Answer:
C
🗳️
A Resource Manager template makes it easy to create the following resources for your application in a single, coordinated operation:
✑ HDInsight clusters and their dependent resources (such as the default storage account).
✑ Other resources (such as Azure SQL Database to use Apache Sqoop).
In the template, you define the resources that are needed for the application. You also specify deployment parameters to input values for different environments.
The template consists of JSON and expressions that you use to construct values for your deployment.
References:
https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-create-linux-clusters-arm-templates
By buying Contributor Access for yourself, you will gain the following features:

